
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- javascript
- API
- CSS
- form
- 알고리즘
- es6
- DRF
- Algorithm
- Django
- react
- django rest framework
- Baekjoon
- PYTHON
- web
- 파이썬
- Git
- django ORM
- django widget
- AWS
- 장고
- MAC
- 백준
- 파이썬 알고리즘
- HTML
- java
- 알고리즘 문제
- c++
- js
- 알고리즘 연습
- 알고리즘 풀이
- Today
- Total
수학과의 좌충우돌 프로그래밍
[Algorithm] 세그먼트 트리(Segment Tree) 본문
세그먼트 트리(Segment Tree)란?
배열에 부분 합을 구할 때 사용하는 개념입니다. 이 때 문제는 배열의 값이 지속적으로 바뀔 수 있기 때문에 매 순간 배열의 부분 길이 만큼, 즉 O(N) 만큼의 시간이 걸리기 때문에 이를 트리로 구현하여 O(logN) 의 시간으로 해결하는 방법입니다.
배열을 세그먼트 트리로
세그먼트 트리 를 사용하기 위해서는 주어진 배열을 이진 트리 구조로 만들어야 합니다. 이 때 트리를 구현하는 알고리즘은 다음과 같습니다.
- 부모노드의 값은 양 쪽 자식 노드 값의 합
- 배열의 요소들은 리프 노드에 위치
위 알고리즘을 통해 N = 10 일 때의 세그먼트 트리를 그리면 다음과 같습니다.

이 때 기존 데이터의 배열의 크기를 통해서 트리 배열의 최대 크기를 알 수 있습니다. 기존 데이터 배열의 크기를 N 이라 하면, 리프 노드의 개수가 N 이 되고, 트리의 높이 H 는 [ logN ] 이 되고, 배열의 크기는 2^(H+1) 이 됩니다.
트리는 단순히 1차원 배열과 인덱싱을 통해 구현할 수 있습니다. 트리의 각 노드 별 배열의 인덱스는 아래 그림과 같습니다.
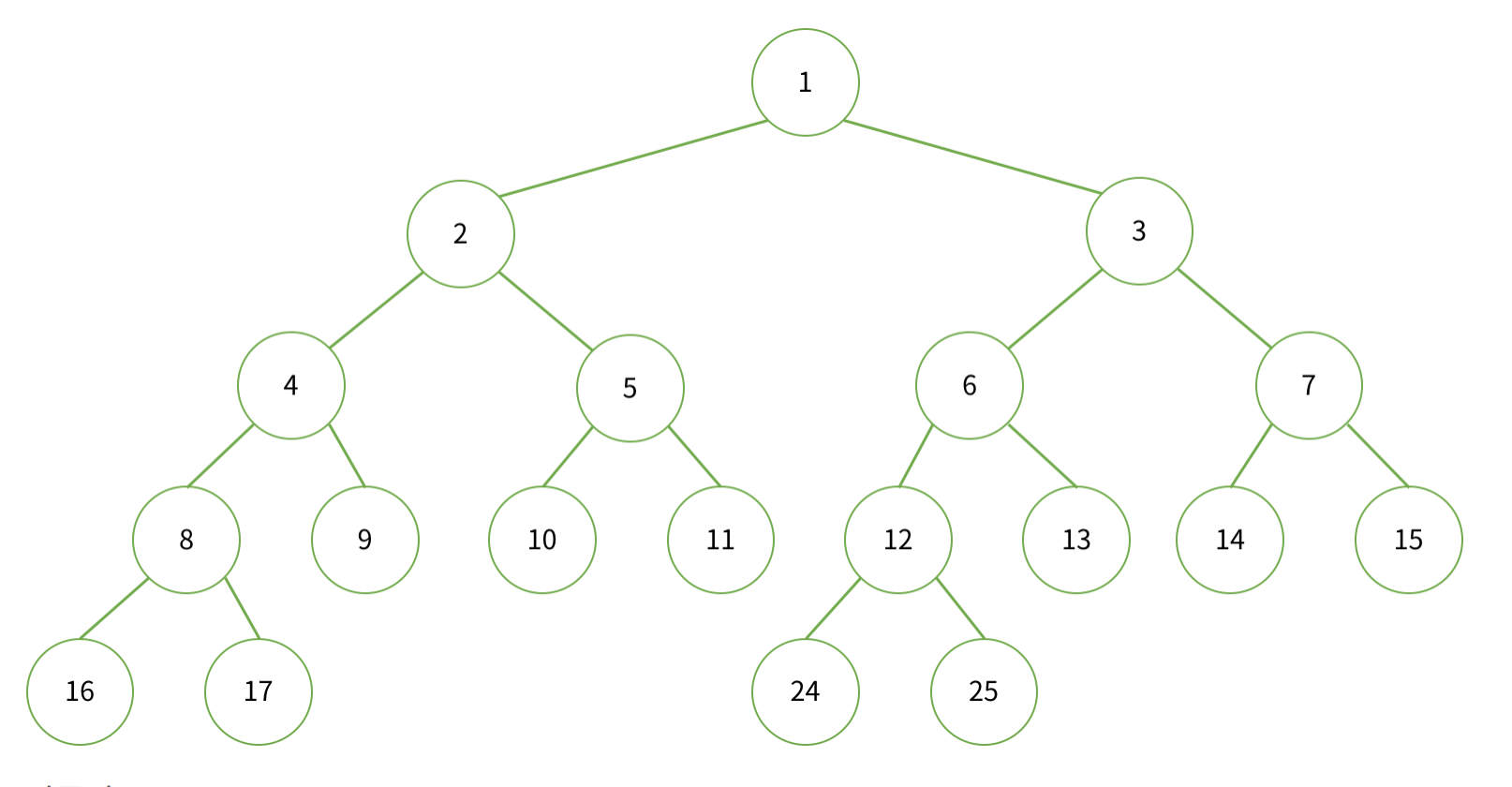
이를 코드로 구현하면 다음과 같습니다.
#include <iostream>
#include <cmath>
using namespace std;
long long *tree;
long long A[10] = {1,2,3,4,5,6,7,8,9,10};
long long init(int index, int start, int end){
if (start == end)
tree[index] = A[start];
else{
int mid = (start+end)/2;
tree[index] = init(index*2+1, start, mid) + init(index*2+2, mid+1, end);
}
return tree[index];
}
int main(int argc, const char * argv[]) {
int N = 10;
int h = ceil(log2(N));
tree = new long long[1<<(h+1)];
init(0,0,N-1);
for (int i=0;i<1<<(h+1);i++){
cout << tree[i] << "\n";
}
return 0;
}
위 그림과 약간의 차이점은 그림은 처음 인덱스를 1부터 시작한데 비해 구현할 때는 0부터 시작하였습니다. 현재 노드의 인덱스 index 에 대해 왼쪽 자식 노드의 인덱스는 index*2+1, 오른쪽 자식 노드의 인덱스는 index*2+2 로서 재귀적으로 구현하였습니다.
구간의 합 구하기
세그먼트 트리를 구현하였으니 이를 이용해서 본래의 목적, 구간의 합을 구해보도록 하겠습니다. 두 구간에 대해서 왼쪽 구간을left, 오른쪽 구간을 right 이라 할 때, 탐색 범위 [start, end] 와 합의 구간 [left, right] 의 관계는 다음과 같습니다.
-
[left, right] 와 [start, end]가 전혀 겹치지 않는 경우
탐색 범위 내에 구하는 범위가 존재하지 않습니다. 그렇다면 탐색 범위에 값들은 아무 의미없는 값이므로 0을 return 합니다.
-
[start, end] 가 [left, right]에 속해 있는 경우
탐색 범위 내에 값들이 전부 구하는 범위의 값들입니다. 하위 노드들을 탐색할 필요없이 이미 하위 노드들의 합을 저장하고 있는
tree[index]를 반환합니다. -
[left, right] 가 [start, end]에 속해 있는 경우
-
[left, right] 와 [start, end] 가 일부 겹치는 경우
해당 경우에는 아직 결론을 내리기에 시기상조입니다. 재귀적으로 더 들어가서 어디까지의 값들이 필요한지에 대해 구해줍니다.
이를 코드로 구현하면 다음과 같습니다.
long long sum(int index, int start, int end, int left, int right){
// 구간이 전혀 겹치지 않는 경우
if (start > right || end < left)
return 0;
else if (left <= start && end <=right)
return tree[index];
else {
int mid = (start+end) / 2;
return sum(index*2+1, start, mid, left, right) + sum(index*2+2, mid+1, end, left, right);
}
}
값 변경하기
마지막으로 배열의 값을 변경해보도록 하겠습니다. 이에 따라 세그먼트 트리의 값도 변경이 되야하죠.
void update(int changed_index, long long diff, int index, int start, int end){
if (changed_index < start || changed_index > end)
return;
tree[index] += diff;
if (start != end){
int mid = (start+end) / 2;
update(changed_index, diff, index*2+1, start, mid);
update(changed_index, diff, index*2+2, mid+1, end);
}
}
여기서 주의해야 할 점은 diff 는 바꿀 새로운 값이 아닙니다. diff = 새로 바꿀 값 - A[changed_index] (기존의 값) 으로서 새로 바꿀 값과 기존의 값의 차이입니다.
-
diff = 새로 바꿀 값 - A[changed_index] (기존의 값)
-
A[changed_index] = 새로 바꿀 값
-
재귀적으로 양 쪽 자식노드로 나눠가며
start == end가 될 때 까지, 즉 리프 노드가 될 때까지 탐색을 합니다. 탐색을 할 시에는 탐색 범위 안에 없다면 return 하고 탐색 범위 안에 있다면 변경된 노드의 증가값 diff 만큼 노드에 더해줍니다.
'알고리즘 > 이론' 카테고리의 다른 글
| [Algorithm] Kruskal 알고리즘 (0) | 2019.11.05 |
|---|---|
| [Algorithm] Spanning Tree 와 MST, 스패닝 트리와 최소 스패닝 트리 (0) | 2019.10.04 |
| [Algorithm] 비트마스크 (0) | 2019.09.23 |
| [Algorithm] 유니온 파인드(Union - Find) (11) | 2019.09.22 |
| [Algorithm] Divide and Conquer, 분할 정복 (0) | 2019.09.20 |



