
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 파이썬
- 알고리즘 문제
- js
- 백준
- HTML
- 파이썬 알고리즘
- django rest framework
- java
- 알고리즘 풀이
- form
- django ORM
- Django
- MAC
- web
- es6
- Git
- API
- javascript
- 장고
- DRF
- 알고리즘 연습
- Baekjoon
- django widget
- AWS
- c++
- 알고리즘
- Algorithm
- PYTHON
- CSS
- react
- Today
- Total
수학과의 좌충우돌 프로그래밍
[python] GIL, Global interpreter Lock은 무엇일까? 본문
파이썬에서 멀티스레드를 사용하려고 한다면 GIL이란 단어를 마주치게 됩니다.
GIL이 무엇인지 파이썬은 왜 GIL을 가지고 있는지 이번 포스팅을 통해 이해해보도록 합시다.
Python으로 멀티스레딩
GIL이 무엇인지 설명 하기 전에 python으로 멀티 스레딩과 일반적인 경우의 시간을 비교해보겠습니다.
시간을 측정하기 전, 현재 테스트 중인 환경을 알아봅시다.
프로세서 : 2.3 GHz 듀얼 코어 Intel Core i5
>> sysctl hw.physicalcpu hw.logicalcpu
hw.physicalcpu: 2
hw.logicalcpu: 4
MacOS의 하이퍼스레딩이란?
랜덤으로 생성한 배열에서 최대값을 찾는 간단한 연산을 두 가지 방법으로 구현해보았습니다.
- 하나의 스레드가 두 개의 작업을 연속적으로 실행
- 두 개의 스레드가 각각 하나의 작업을 실행
import random
import threading
import time
def working():
max([random.random() for i in range(500000000)])
# 1 Thread
s_time = time.time()
working()
working()
e_time = time.time()
print(f'{e_time - s_time:.5f}')
# 2 Threads
s_time = time.time()
threads = []
for i in range(2):
threads.append(threading.Thread(target=working))
threads[-1].start()
for t in threads:
t.join()
e_time = time.time()
print(f'{e_time - s_time:.5f}')
당연히 혼자하는 것보다 둘이 하는게 나을테니 멀티스레딩을 한 경우 성능 향상을 기대할 수 있습니다.
하지만 결과는 다음과 같이 멀티스레딩의 성능이 오히려 나쁜 것을 확인할 수 있습니다.
GIL
위와 같은 원인을 설명하기 위해서는 GIL에 대한 설명이 필요합니다.
GIL이란 Global Interpreter Lock의 약자로 파이썬 인터프리터가 한 스레드만 하나의 바이트코드를 실행 시킬 수 있도록 해주는 Lock입니다.
하나의 스레드에 모든 자원을 허락하고 그 후에는 Lock을 걸어 다른 스레드는 실행할 수 없게 막아버리는 것이죠.
스레드 3개를 통해 작업을 하는 경우를 생각해봅시다.
일반적인 경우에는 각각의 스레드가 병렬적으로 일할 것이라 생각되지만 이 GIL 때문에 그렇지 않습니다.
아래 그림을 python에서 3개의 스레드가 동작하는 예시입니다.
각각의 스레드는 GIL을 얻고 동작하며 이 때 다른 스레드는 모두 동작을 멈추게 됩니다.
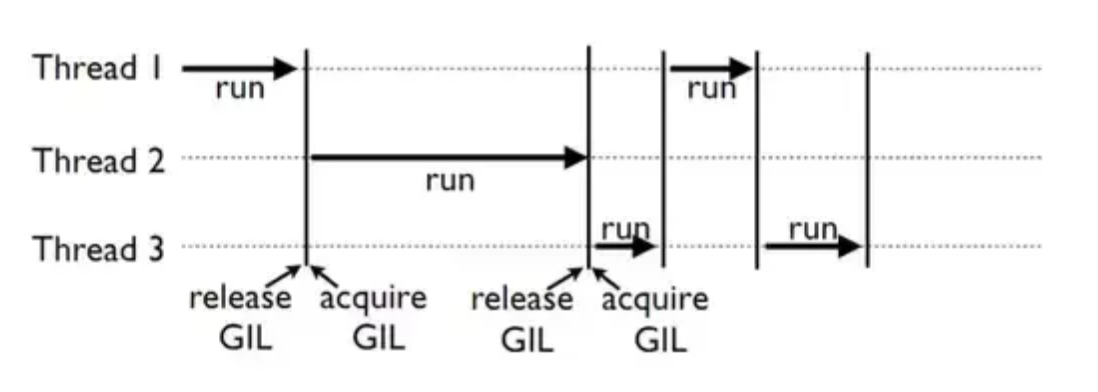
그리고 멀티스레드일 경우 thread context switch에 따른 비용도 발생하기 때문에 오히려 싱글스레드보다 시간이 오래 걸리는 문제가 발생합니다.
굳이 왜 GIL을?
그렇다면 python에서 굳이 GIL을 사용하는 이유에 대해서 알아봅시다.
python은 기본적으로 garbage collection과 reference counting을 통해 할당된 메모리를 관리합니다.
둘 모두 중요한 개념이고 설명할 게 끝도 없으나 주제에 벗어나므로 다른 포스팅에서 다루도록 하겠습니다.
따라서 파이썬의 모든 객체는 refernce count, 즉 해당 변수가 참조된 수를 저장하고 있습니다.
여기서 문제가 발생합니다.
멀티스레드인 경우 여러 스레드가 하나의 객체를 사용한다면 refernce count를 관리하기 위해서 모든 객체에 대한 lock이 필요할 것입니다.
이러한 비효율을 막기 위해서 python에서 GIL을 사용하게 되었습니다.
하나의 Lock을 통해서 모든 객체들에 대한 refernce count의 동기화 문제를 해결한 것이죠.
python 멀티스레딩은 무조건 느리다?
위의 예시를 통해 일반적인 연산의 경우, 멀티스레드가 싱글스레드보다 느린 것을 확인하였습니다.
GIL로 인해서 무조건 멀티스레드가 느릴까요?
다음의 예시를 살펴봅시다.
import random
import threading
import time
def working():
time.sleep(0.1)
max([random.random() for i in range(10000000)])
time.sleep(0.1)
max([random.random() for i in range(10000000)])
time.sleep(0.1)
max([random.random() for i in range(10000000)])
time.sleep(0.1)
max([random.random() for i in range(10000000)])
time.sleep(0.1)
max([random.random() for i in range(10000000)])
time.sleep(0.1)
# 1 Thread
s_time = time.time()
working()
working()
e_time = time.time()
print(f'{e_time - s_time:.5f}')
# 2 Threads
s_time = time.time()
threads = []
for i in range(2):
threads.append(threading.Thread(target=working))
threads[-1].start()
for t in threads:
t.join()
e_time = time.time()
print(f'{e_time - s_time:.5f}')
놀랍게도 다음의 예시는 멀티스레드에서 성능이 개선된 것을 확인할 수 있습니다.
37.50009
29.40628
그 이유는 바로 sleep입니다.
싱글스레드에서는 sleep으로 인해 아무런 동작도 취하지 못한 체 동작을 대기하는 반면에 멀티스레드에서는 sleep으로 멈춘 경우 다른 스레드로 context switching하여 효율이 개선됩니다.
지금은 설명하기 위해 sleep 함수를 사용하였지만 일반적인 경우 I/O 작업이 많아 스레드가 대기해야 할 경우 위에서 설명한 것과 같은 이유로 멀티스레드의 성능이 더 좋을 수 있습니다.
'프로그래밍 언어 > Python' 카테고리의 다른 글
| [python] Type Hints, python에 타입을 지정한다? (5) | 2021.06.20 |
|---|---|
| [python] Decimal vs Float, 고정소수점과 부동소수점 (3) | 2020.06.10 |
| [python] 파이썬의 정렬, Tim Sort (2) | 2020.06.03 |
| [python] 언패킹, *args, **kwargs (0) | 2019.10.28 |
| [python] 장식자, 데코레이터(decorator) 를 알아보자 (8) | 2019.08.08 |



