
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- django widget
- form
- 파이썬 알고리즘
- 알고리즘 풀이
- 백준
- web
- Django
- HTML
- Algorithm
- es6
- javascript
- react
- java
- Baekjoon
- 알고리즘
- 장고
- c++
- django rest framework
- 파이썬
- PYTHON
- js
- Git
- 알고리즘 문제
- CSS
- django ORM
- MAC
- DRF
- AWS
- API
- 알고리즘 연습
- Today
- Total
수학과의 좌충우돌 프로그래밍
Google Vision API 를 사용한 글자 인식 본문
google cloud vision API 를 활용한 글자인식
사전 준비
vision API 뿐만 아니라 다른 google API를 사용하기 위해서도 사전준비가 필요합니다. 이에 대해 알아보도록 하겠습니다. 먼저 아래 url 로 접속합니다.
http://console.developers.google.com
이 곳에서 우리는 사용자 인증 정보를 만들고 API 를 사용할 수 있는 key 를 받을 수 있습니다.

좌측 메뉴바에서 사용자 인증 정보 로 이동하면 사용자 인증 정보 만들기 라는 버튼을 찾을 수 있습니다.

버튼을 클릭하면 인증 정보를 만들 수 있는 다양한 방식을 선택할 수 있습니다. 서비스 계정 키를 이용해서 만들어보도록 하겠습니다.
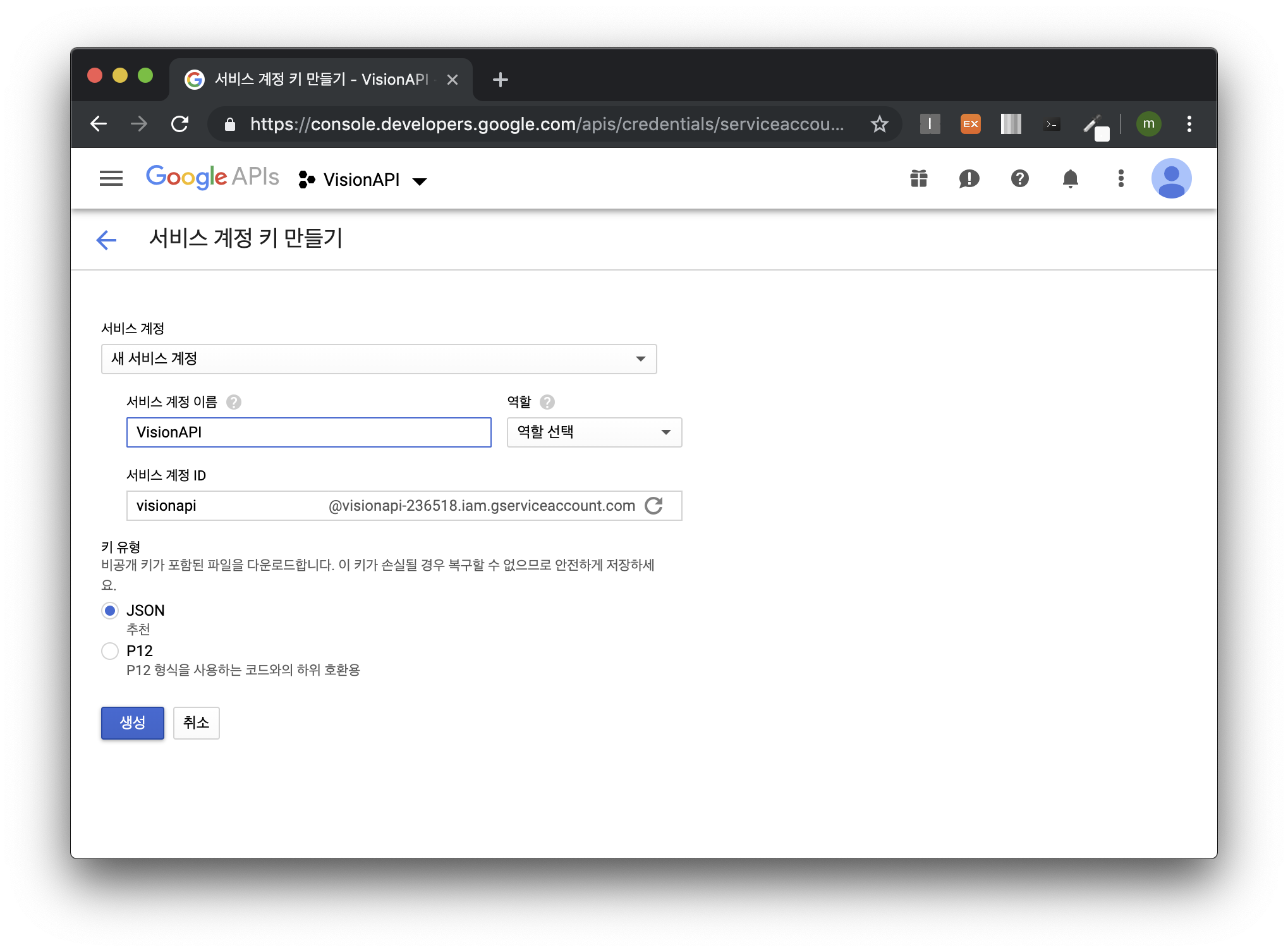
계정이름과 계정 ID를 적어주고 키 유형은 JSON 을 이용해서 받도록 하겠습니다. 이 때 역할은 선택하지 않습니다.

그 결과, json 형식의 파일이 하나 다운 받아졌습니다. 이 파일을 key로서 사용하게 될 것입니다. 이 key 만 있다면 다른 사용자도 cloud과 통신할 수 있으므로 노출해서는 안됩니다.

키가 만들어진 것을 확인했다면 local 로 넘어와보도록 하겠습니다. 우선 vision API 를 사용하기 위해서 이 라이브러리를 설치해야합니다. pip 를 통해서 설치하도록 하겠습니다.
pip install google-cloud-vision

설치가 다 완료되었으면 작업 공간을 만들어주겠습니다. 바탕화면에 Vision API 라는 디렉토리를 만들고 이 안에 아까 다운받았던 json 파일도 가져오도록 하겠습니다.
terminal 에서 현재 경로를 확인해보면 다음과 같습니다.
pwd #/Users/rkdalstjd9/desktop/VisionAPI
이제 API 를 사용할 VisionAPI.py 를 만들고 환경변수를 설정해주도록 하겠습니다. terminal에서 아래의 명령어를 입력해줍니다.
export GOOGLE_APPLICATION_CREDENTIALS="/Users/rkdalstjd9/desktop/VisionAPI/VisionAPI-9a8f1b0d454a.json"
위에서 확인한 현재 작업공간의 경로에 아까 다운받은 json 파일을 지정해줍니다. 그렇게 때문에 위의 명령어는 사용자마다 다를 것입니다.
실습하기
드디어 사전준비가 모두 끝났습니다. 이제 API 가 잘 동작하는지 확인해보도록 하죠.
import io
def detect_text(path):
from google.cloud import vision
client = vision.ImageAnnotatorClient()
with io.open(path, 'rb') as image_file:
content = image_file.read()
image = vision.types.Image(content=content)
먼저 detect_text 라는 함수를 정의합니다. 파리미터로 이미지 파일의 경로를 받아 그 이미지 내의 글자를 인식하게 되죠. 여기까지는 이미지를 vision API가 읽을 수 있는 형태로 가공해주는 과정입니다.
response = client.text_detection(image=image)
texts = response.text_annotations
text_dection 으로 인해 정보를 추출합니다.
respose에는 상세한 정보들이 저장됩니다. 어느 언어로 인식 했는지 부터 문장 별, 단어 별, 각 철자 별 어떻게 인식을 하였는지, 이미지에서 위치는 어디에 있는지 상세 정보들이 담기게 됩니다.texts에는 response 에서 내용을 좀 더 간추립니다. 철자는 제외하고 문장과 단어에 대한 정보만 담기게 됩니다.
for text in texts:
print('\n"{}"'.format(text.description))
vertices = (['({},{})'.format(vertex.x, vertex.y)
for vertex in text.bounding_poly.vertices])
print('bounds: {}'.format(','.join(vertices)))
그 후 texts 에 담긴 정보의 가시성을 높이기 위해 약간의 가공을 해줍니다.
import os
file_name = os.path.join(
os.path.dirname(__file__),
'Hello_world.png')
detect_text(file_name)
마지막으로 이미지의 경로를 설정하고 함수를 실행시켜줍니다.
전체 코드는 다음과 같습니다.
import os, io
def detect_text(path):
from google.cloud import vision
client = vision.ImageAnnotatorClient()
with io.open(path, 'rb') as image_file:
content = image_file.read()
image = vision.types.Image(content=content)
response = client.text_detection(image=image)
texts = response.text_annotations
print('Texts:')
for text in texts:
print('\n"{}"'.format(text.description))
vertices = (['({},{})'.format(vertex.x, vertex.y)
for vertex in text.bounding_poly.vertices])
print('bounds: {}'.format(','.join(vertices)))
file_name = os.path.join(
os.path.dirname(__file__),
'Hello_world.png')
detect_text(file_name)
이미지와 이미지의 결과는 다음과 같습니다.
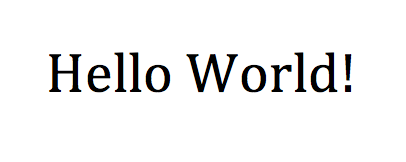
Texts:
"Hello World!"
bounds: (48,52),(351,52),(351,91),(48,91)
"Hello"
bounds: (48,52),(170,52),(170,91),(48,91)
"World!"
bounds: (185,52),(351,52),(351,91),(185,91)
이미지 내에서 철자의 위치를 각 꼭지점의 좌표를 통해서 표시를 해줍니다. 좌측 하단부터 시계 반대 방향으로 좌표를 나타냅니다.
다행스럽게도 영어 외의 다른 언어들도 지원을 합니다. 지원하는 언어는 아래 url에서 확인할 수 있습니다.
https://cloud.google.com/vision/docs/languages