
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- js
- java
- 알고리즘
- AWS
- Algorithm
- 백준
- 파이썬 알고리즘
- 알고리즘 문제
- 알고리즘 풀이
- web
- HTML
- API
- form
- PYTHON
- Django
- 장고
- django widget
- c++
- es6
- MAC
- django rest framework
- CSS
- Git
- react
- 알고리즘 연습
- DRF
- 파이썬
- django ORM
- Baekjoon
- javascript
- Today
- Total
수학과의 좌충우돌 프로그래밍
[딥러닝]Neural Style Transfer 본문
Intro
사진을 찍던 중 사진의 스타일을 바꿀 수 있는 걸 보고 새삼스럽게 든 생각. 이건 어떻게 구현하지? 그래서 이를 한 번 구현해보고자 하였습니다,
이에 대해서 찾아보니 이름은 뉴럴 스타일 트랜스퍼 로 2015년 리온 게티스에 의해 ‘A Neural Algorithm of Artistic Style ’ 논문으로 처음 세상에 알려졌습니다. 이 방식은 타겟 이미지의 콘텐츠는 보존하면서 참조 이미지의 스타일을 타깃 이미지에 적용하는 방식입니다.
아래 사진을 살펴보면, 첫 번째 사진은 독일의 튀빙겐이라는 곳에서 찍은 사진으로 타깃이미지가 되고, 두 번째 사진은 이를 빈센트 반 고흐의 '별이 빛나는 밤' 을 스타일 이미지로서 합친 사진입니다. 스타일이라고 함은 질감, 색깔, 이미지 등 다양한 크기의 시각 요소를 의미합니다.

CNN
스타일 트렌스퍼의 핵심 개념은 딥러닝 알고리즘의 핵심과 동일합니다. CNN 을 사용한다는 점까지 말이죠. 하지만 CNN 을 어떻게 사용하는지에 대한 접근이 다릅니다. 기존에는 각각의 layer 가 feature 를 생성해내고 이를 쌓아서 layer가 깊어진다면 더 좋은 feature를 만들어냅니다. 하지만 이번에는 이를 반대로 하게 되죠. 오히려 생성한 Feature map 로 부터 이미지를 reconstruction 하는 것이죠.
이 때 타겟이미지는 layer를 깊게 들어가서는 안됩니다. 네트워크에 있는 하위 층의 활성화는 이미지 어느 한 부분에 대한 한정된 정보를 나타내고 상위 층의 활성화는 전체적으로 추상적인 정보를 나타내기 때문에 타겟이미지는 전체적으로 추상적인 정보를 나타내야하죠.

그리고 CNN 모델 중 기존에 존재하던 VGG19 를 가져와 사용합니다. VGG19 는 아래 네모친 부분과 같으며 원래의 VGG19 와는 조금 다른 점이 있습니다. pooling 을 기존에는 max pooling을 사용한데 비해 여기서는 average pooling을 사용합니다. 그 이유는 단지 여러 pooling 을 적용해봤을 때, average pooling이 제일 좋은 결과가 나왔기 때문이라고 생각합니다.
손실함수
기존에는 목표를 표현한 손실함수를 정하고 이 손실을 최소화 합니다. 그렇다면 이 경우 손실함수를 어떻게 정의하는 것이 좋을까요? 결론부터 말하자면 다음과 같습니다.
loss = distance(style(reference_image)-style(generated_image)) + distance(content(original_image)-content(generated_image))
여기서 distance 함수는 Norm 함수를 의미합니다. 그리고 여기서는 L2 Norm 과 같은 방식으로 구성되어 있기 때문에 loss 를 최소화하면 reference_image 와 original_image 는 generated_image 와 같아지게 됩니다.
콘텐츠 손실
여기서 알고 넘어가야 하는 사실은 네트워크에 있는 하위 층의 활성화는 이미지 전체에 대해서 어느 한 부분에 한정되어 있는 정보를 담고 있습니다. 그에 비해 상위 층의 활성화는 전체적으로 추상적인 정보를 담게 됩니다. 상위층에서 보았을 때 생성된 이미지와 원본 이미지가 비슷하게 만들어질거라 예측할 수 있기 때문에 우리는 상위 층의 활성화로 계산을 할 것입니다. 이로서 우리는 원래 이미지의 전체적인 느낌을 보존할 수 있습니다. 이 때 콘텐츠 손실은 하나의 상위 층만을 사용할 것입니다.
스타일 손실
스타일 손실은 반대로, 컨브넷의 여러 층을 사용합니다. 여기서 활성화 출력의 그람 행렬을 스타일 손실로 사용했습니다. 그람 행렬은 아래 그림과 같이 각 층의 특성 맵들을 내적 값이 성분이 되는데 내적을 함으로서 층의 특성 사이에 있는 상관관계를 표현한다고 이해할 수 있습니다.
케라스로 구현하기
먼저 개발 환경은 google의 colab 을 사용하였습니다. GPU를 사용할 수 있기 때문에 빠른 시간 내에 트레이닝이 가능합니다. colab에서 이미지를 업로드 하기 위해서는 조금 다른 방법을 사용합니다.
from google.colab import files
uploaded = files.upload()
for fn in uploaded.keys():
print('user uploaded file "{name}" with length {length} bytes'.format(name=fn,length=len(uploaded[fn])))
# user uploaded file "portrait.png" with length 57696 bytes
# user uploaded file "popova.jpg" with length 100154 bytes
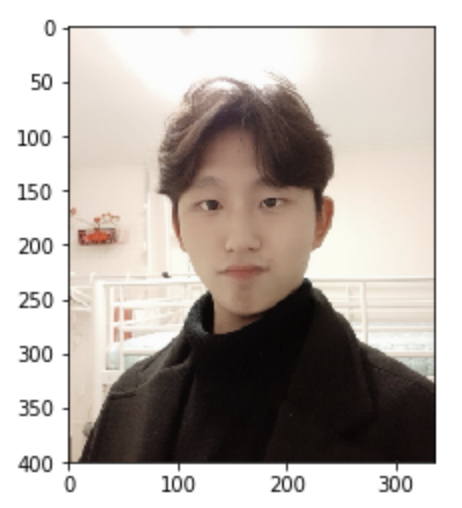
파일을 업로드 할 수 있는 form 생기고 직접 원하는 이미지를 업로드 할 수 있습니다. 저는 제 이미지와 러시아 화가 popova의 이미지를 업로드 해보도록 하겠습니다.
import keras
from keras.preprocessing.image import load_img, img_to_array, save_img
# 변환하려는 이미지 경로
target_image_path = './portrait.jpeg'
# 스타일 이미지 경로
style_reference_image_path = './popova.jpg'
# 생성된 사진의 차원
width, height = load_img(target_image_path).size
img_height = 400
img_width = int(width * img_height / height) # 비율에 맞춰서 줄여준다.
이미지의 높이를 400으로 고정시키고 비율이 맞게끔 너비로 변환해주었습니다.
다음으로는 사전 훈련된 컨브넷 중 어떤 것을 사용하던 문제 없지만 VGG19 를 사용하도록 하겠습니다. VGG19에 이미지 로드, 전처리, 사후 처리를 위한 함수를 정의하도록 하겠습니다.
import numpy as np
from keras.applications import vgg19
def preprocess_image(image_path):
img = load_img(image_path, target_size=(img_height, img_width))
img = img_to_array(img)
img = np.expand_dims(img, axis=0)
img = vgg19.preprocess_input(img)
return img
def deprocess_image(x):
# VGG19.preprocess_input 함수에서 일어나는 변환을 복원하기 위해
# ImageNet의 평균 픽셀 값을 더하고
x[:, :, 0] += 103.939
x[:, :, 1] += 116.779
x[:, :, 2] += 123.68
# 'BGR'->'RGB' 으로 변환합니다.
x = x[:, :, ::-1]
x = np.clip(x, 0, 255).astype('uint8')
return x
이제 VGG19 네트워크를 설정해보도록 하겠습니다.
from keras import backend as K
# 이미 준비되어있는 이미지 이므로 constant를 이용해서 정의
target_image = K.constant(preprocess_image(target_image_path))
style_reference_image = K.constant(preprocess_image(style_reference_image_path))
# 생성된 이미지를 담을 플레이스홀더
combination_image = K.placeholder((1, img_height, img_width, 3))
# 세 개의 이미지를 하나의 배치로 합칩니다
input_tensor = K.concatenate([target_image,
style_reference_image,
combination_image], axis=0)
# 세 이미지의 배치를 입력으로 받는 VGG 네트워크를 만듭니다.
# 이 모델은 사전 훈련된 ImageNet 가중치를 로드합니다
model = vgg19.VGG19(input_tensor=input_tensor,
weights='imagenet',
include_top=False)
print('모델 로드 완료.')
input_tensor 는 타깃이미지, 스타일 이미지, 생성된 이미지를 행으로 쌓게 됩니다. 결국 input_tensor의 차원은 (3,400,width,3) 이 됩니다.
다음으로 콘텐츠 손실과 스타일 손실을 정의해보도록 하겠습니다.
def content_loss(base, combination):
return K.sum(K.square(combination - base))
def gram_matrix(x):
features = K.batch_flatten(K.permute_dimensions(x, (2, 0, 1)))
gram = K.dot(features, K.transpose(features))
return gram
def style_loss(style, combination):
S = gram_matrix(style)
C = gram_matrix(combination)
channels = 3
size = img_height * img_width
return K.sum(K.square(S - C)) / (4. * (channels ** 2) * (size ** 2))
두 손실 함수에 하나의 손실함수를 더 사용합니다.
def total_variation_loss(x):
a = K.square(
x[:, :img_height - 1, :img_width - 1, :] - x[:, 1:, :img_width - 1, :])
b = K.square(
x[:, :img_height - 1, :img_width - 1, :] - x[:, :img_height - 1, 1:, :])
return K.sum(K.pow(a + b, 1.25))
생성된 이미지의 픽셀을 사용하여 계산하는 총 변위 손실 입니다. 이로서 생성된 이미지가 공간적인 연속성을 가지도록 도와주며 픽셀의 격자 무늬가 과도하게 나타나는 것을 막아줍니다. 일종의 규제라고 생각하면 됩니다.
최소화할 최종 손실 정의하도록 하겠습니다. 이는 앞에서 봤던 세 개의 손실 함수의 평균입니다. 콘텐츠 손실은 block5_conv2 층 하나만을 사용해서 계산하고, 스타일 손실을 계산하기 위해서는 하위 층과 상위 층에 걸쳐 여러 층을 사용해야합니다. 그리고 마지막으로 총 변휘 손실을 추가해줍니다. 이 때 content_weight 는 생성된 이미지에 타깃 콘텐츠가 얼마나 나타나는지를 조정합니다. 크기가 클수록 더 많이 나타나게 됩니다.
# 층 이름과 활성화 텐서를 매핑한 딕셔너리
outputs_dict = dict([(layer.name, layer.output) for layer in model.layers])
# 콘텐츠 손실에 사용할 층
content_layer = 'block5_conv2'
# 스타일 손실에 사용할 층
style_layers = ['block1_conv1',
'block2_conv1',
'block3_conv1',
'block4_conv1',
'block5_conv1']
# 손실 항목의 가중치 평균에 사용할 가중치
total_variation_weight = 1e-4
style_weight = 1.
content_weight = 0.025
# 모든 손실 요소를 더해 하나의 스칼라 변수로 손실을 정의합니다
loss = K.variable(0.)
layer_features = outputs_dict[content_layer]
target_image_features = layer_features[0, :, :, :]
combination_features = layer_features[2, :, :, :]
loss += content_weight * content_loss(target_image_features,
combination_features)
for layer_name in style_layers:
layer_features = outputs_dict[layer_name]
style_reference_features = layer_features[1, :, :, :]
combination_features = layer_features[2, :, :, :]
sl = style_loss(style_reference_features, combination_features)
loss += (style_weight / len(style_layers)) * sl
loss += total_variation_weight * total_variation_loss(combination_image)
# 손실에 대한 생성된 이미지의 그래디언트를 구합니다
grads = K.gradients(loss, combination_image)[0]
# 현재 손실과 그래디언트의 값을 추출하는 케라스 Function 객체입니다
fetch_loss_and_grads = K.function([combination_image], [loss, grads])
마지막으로 경사하강법을 설정합니다. 케티스의 논문을 살펴보면 L-BFGS 알고리즘을 사용합니다. 이 알고리즘은 두 가지 문제점이 있습니다.
- 손실 함수 값과 그래디언트 값을 별개의 함수로 전달해야 함
- 3D 이미지 배열이 아니라 1차원 벡터만 처리할 수 있음
손실 함수와 그래디언트 값을 따로 계산하는 것은 비효율적입니다. 두 계산 사이에 중복되는 연산이 많기에 따로 할 경우, 거의 2배 가까이 느립니다. 이를 피하기위해 케티스는 새로운 클래스를 정의하여 이를 해결합니다.
class Evaluator(object):
def __init__(self):
self.loss_value = None
self.grads_values = None
def loss(self, x):
assert self.loss_value is None
x = x.reshape((1, img_height, img_width, 3))
outs = fetch_loss_and_grads([x])
loss_value = outs[0]
grad_values = outs[1].flatten().astype('float64')
self.loss_value = loss_value
self.grad_values = grad_values
return self.loss_value
def grads(self, x):
assert self.loss_value is not None
grad_values = np.copy(self.grad_values)
self.loss_value = None
self.grad_values = None
return grad_values
evaluator = Evaluator()
처음 호출할 때 손실 값을 반환하면서 다음 호출을 위해 그래디언트를 캐싱합니다.
이제 경사하강법 단계를 실행하겠습니다.
from scipy.optimize import fmin_l_bfgs_b
import time
result_prefix = 'style_transfer_result'
iterations = 20
x = preprocess_image(target_image_path) # 초기 값은 타깃 이미지입니다
x = x.flatten() # scipy.optimize.fmin_l_bfgs_b 함수가 벡터만 처리할 수 있기 때문에 이미지를 펼칩니다.
for i in range(iterations):
print('반복 횟수:', i)
start_time = time.time()
x, min_val, info = fmin_l_bfgs_b(evaluator.loss, x,
fprime=evaluator.grads, maxfun=20)
# 뉴럴 스타일 트랜스퍼의 손실을 최소화하기 위해 생성된 이미지에 대해 L-BFGS 최적화를 수행합니다
print('현재 손실 값:', min_val)
# 생성된 현재 이미지를 저장합니다
img = x.copy().reshape((img_height, img_width, 3))
img = deprocess_image(img)
fname = result_prefix + '_at_iteration_%d.png' % i
save_img(fname, img)
end_time = time.time()
print('저장 이미지: ', fname)
print('%d 번째 반복 완료: %ds' % (i, end_time - start_time))
최종적으로 이미지가 완성되는 걸 확인할 수 있습니다.


'인공지능 > 케라스창시자에게 배우는 딥러닝' 카테고리의 다른 글
| [딥러닝]05.imdb 영화 리뷰 이진 분류 (1) | 2019.03.25 |
|---|---|
| [딥러닝]05. 신경망의 구조 (0) | 2019.03.18 |
| [딥러닝]04.그레디언트 (0) | 2019.03.15 |
| [딥러닝]03.텐서연산 (0) | 2019.03.15 |
| [딥러닝]02.신경망을 위한 데이터 표현 (0) | 2019.03.15 |



